本章为第一讲的学习笔记:深度学习基本概念简介(下),视频链接,slides。
Model的类型
Linear model:
- $y = b + wx_1$ (单个特征)
- $y = b + \sum_j w_j x_j$ (多个特征)
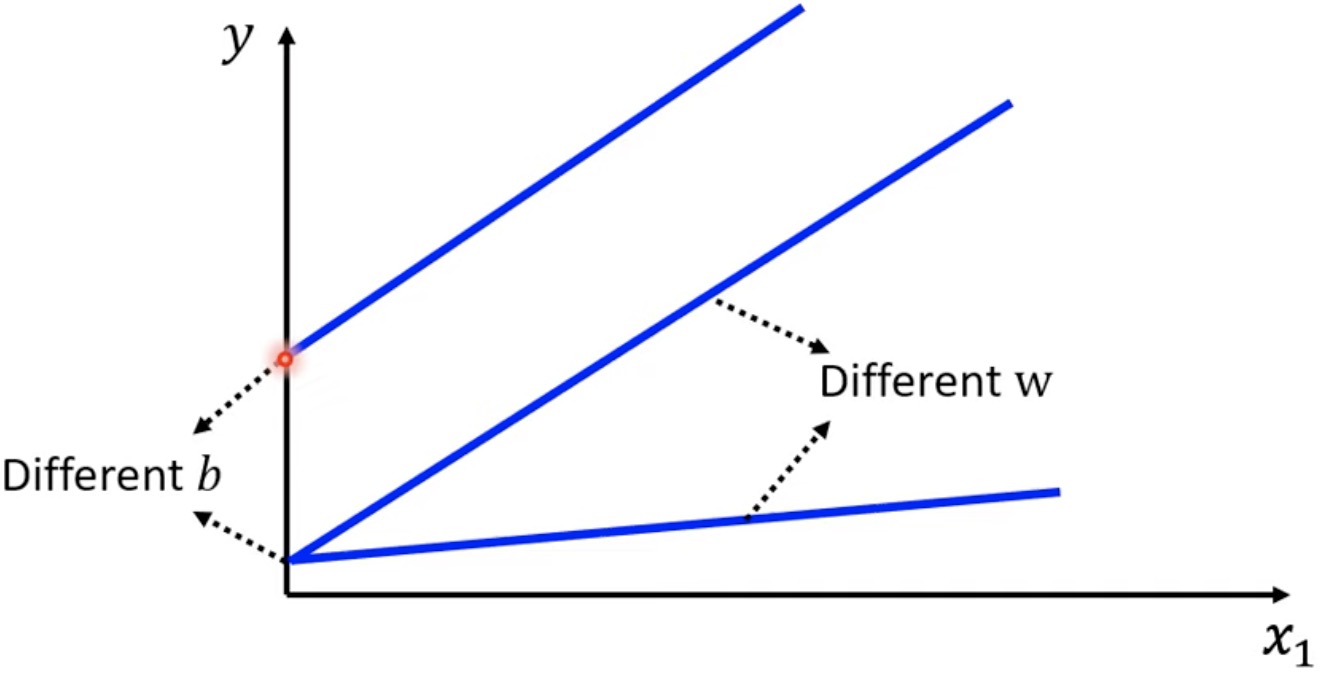
Piecewise Linear model:可以用Sigmoid 或 Rectified Linear Unit (ReLU) 等 Activation Function 来表示。
Sigmoid:$ sigmoid ( x ) = \frac { 1 } {1 + e ^{ - x} }$.
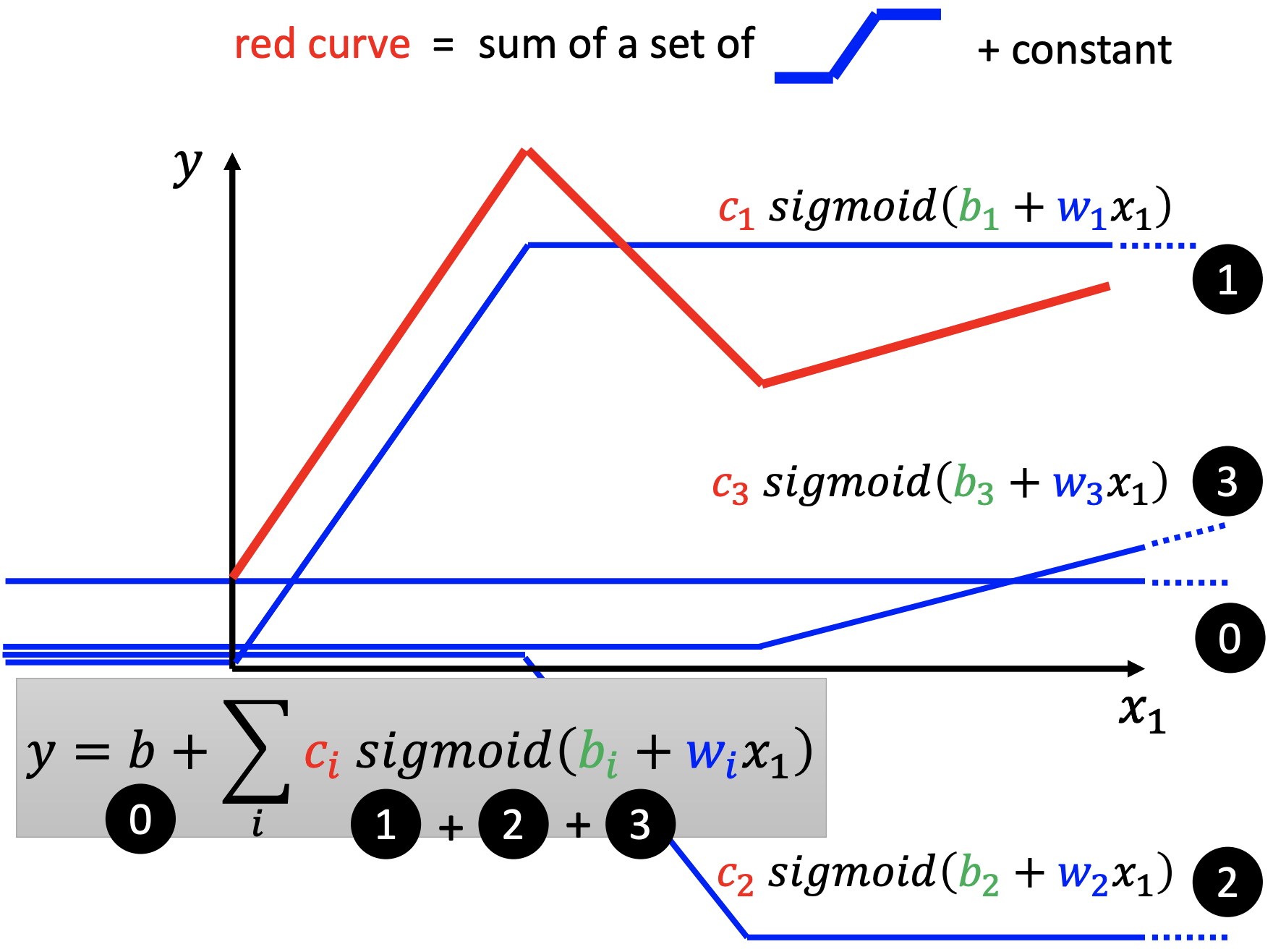
- $ y = b + \sum _ i c_i sigmoid (b_i + w_i x_1)$ (单个特征)
- $y = b + \sum_i c_i sigmoid (b_i + \sum_j w_{ i j } x_j) $ (多个特征)
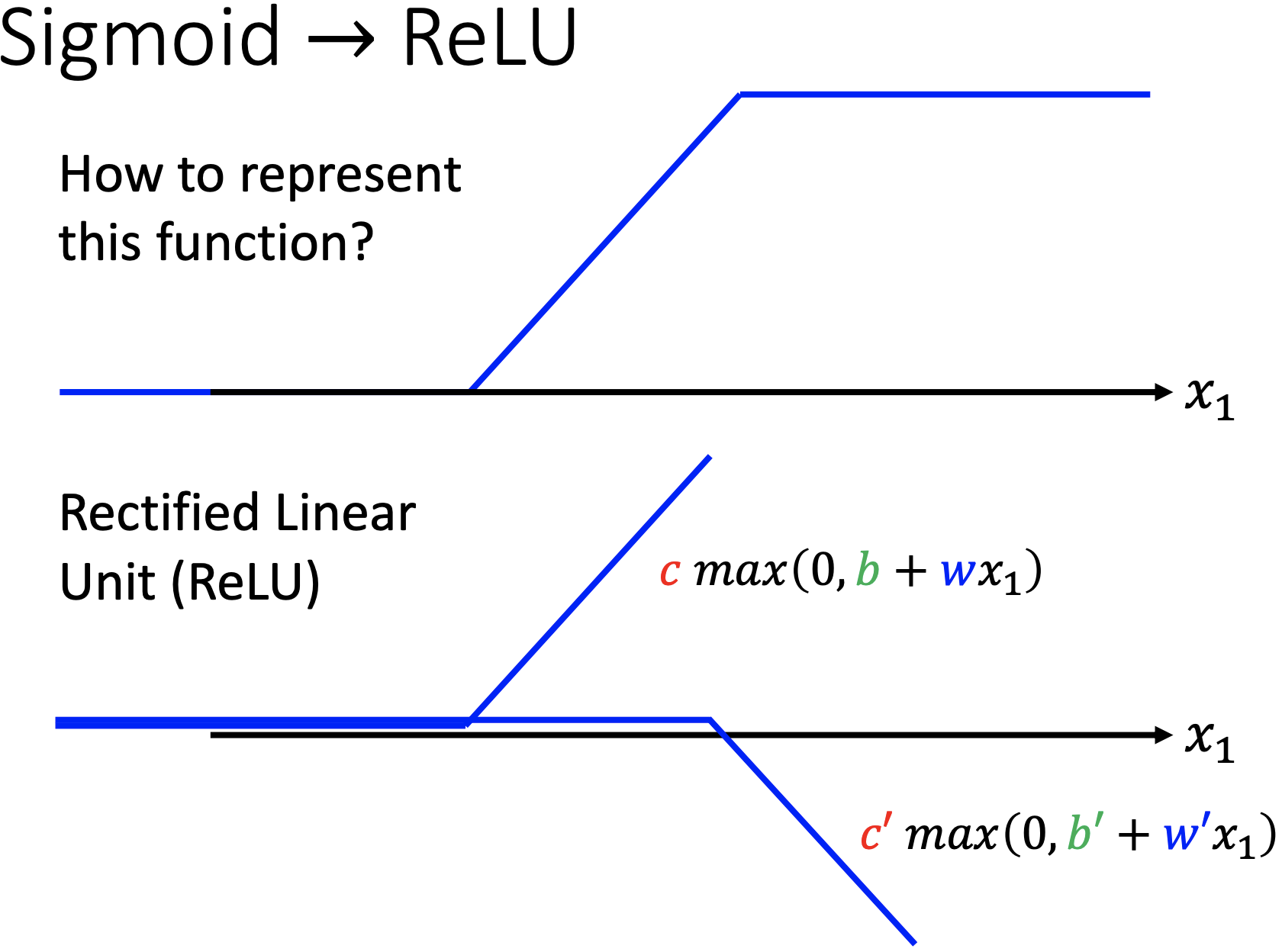
ReLU: ReLU和Sigmoid相比更加好。
- $y = b + \sum_{2i} c_i max(0, b_i + w_i x_1)$ (单个特征)
- $y = b + \sum_{2i} c_i max(0, b_i + \sum_j w_{ij} x_j)$ (多个特征)这里 sum 的是 $2i$ 是因为两个 ReLU 才能合成一个 sigmoid。
How to find a function?
找function的方法和Liner Model的一样。
首先为了方便,把所有的未知参数用向量$\Theta $来表示,$\Theta$中包括了上式中的所有$b$, $c_i$, $b_i$, $w_i$。
随机找一组$\Theta$ , 计作 $\Theta_0$.
计算Gradient,根据 Gradient 把 $\Theta_i$更新成$\Theta_ {i+1}$
重复步骤 2 直至指定的计算次数 或 算出的 Gradient 为 $0$ 向量.
实际上,在做 Gradient Decent 的时候,会把原始数据分成一个一个的Batch。用第 $i$ 个 Batch 里的 Data 算 Loss ,然后更新 $\Theta _i$ ,然后用更新后的 $\Theta_i$ 来对第 $i+1$ 个 Batch 的 Data 算 Loss 然后继续更新。每一次更新参数叫做一次 Update 。遍历完所有的 Batch 之后叫做一个 Epoch 。Batch 的 Size 也是一个 hyperparameter 。
一些新名字
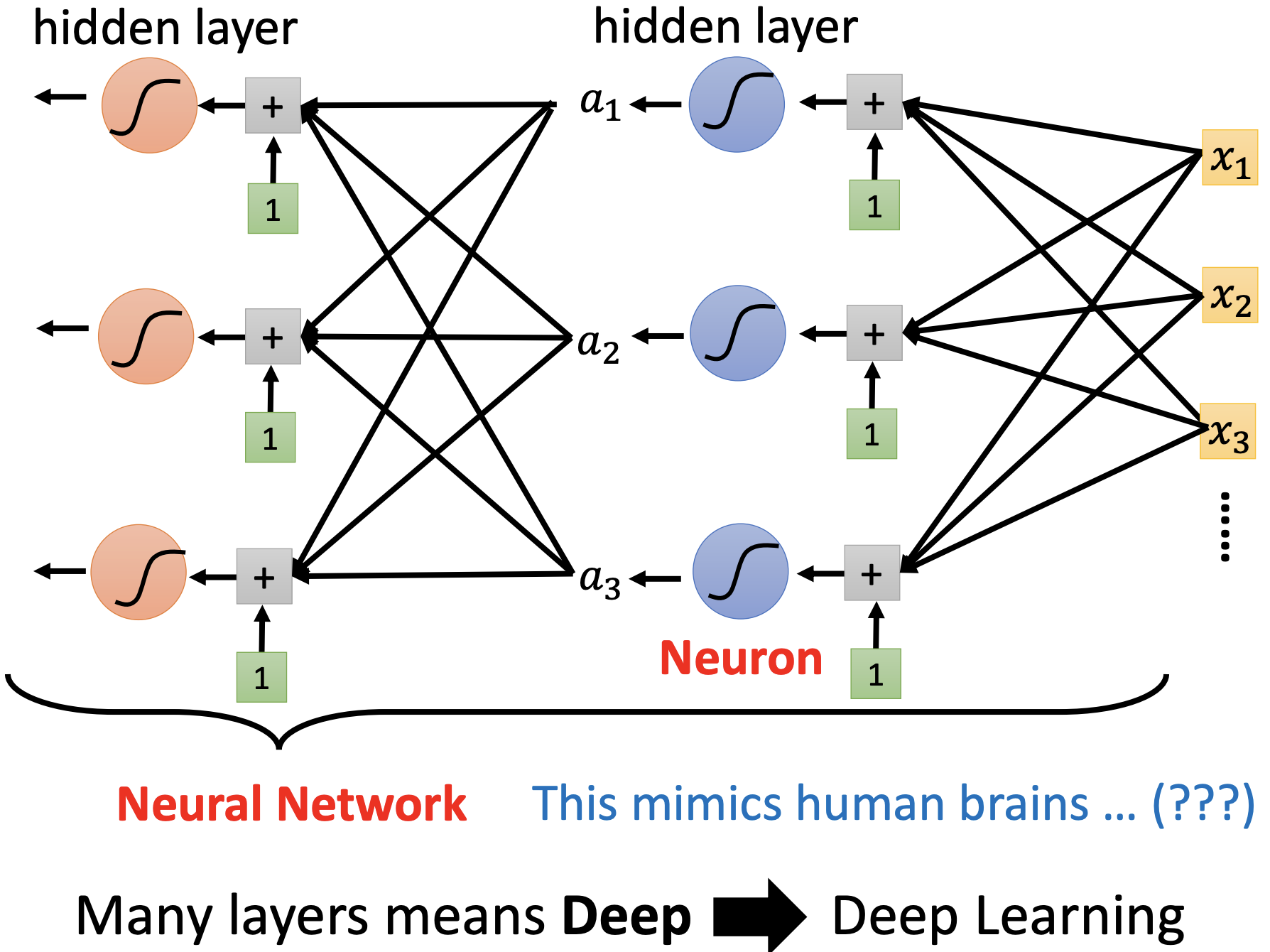
Neuron, Neural Network, hidden layer, DeepLearning 如图所示,其中$a_i = sigmoid (b_i + \sum_j w_{ ij } x_j )$ 或 $a_i = max(0, b_i + \sum_j w_{ij} x_j)$。
Overfitting:在训练资料上在变好,但是在实际上没有变好。